

Anonymisation, pseudonymisation, archivage - Sur la route du RGPD.
 L’arrivée du Règlement Général sur la Protection des Données (RGPD), qui doit permettre aux citoyens de reprendre le contrôle de leurs données personnelles, modifie radicalement les politiques de conservation à long terme des données et métadonnées archivées, ce depuis leur collecte, désormais soumise aux conditions de licéité de l’article 6 du RGPD (essentiellement accord de la personne concernée, ou obligations réglementaires), jusqu’au traitement du sort final des informations conservées.
L’arrivée du Règlement Général sur la Protection des Données (RGPD), qui doit permettre aux citoyens de reprendre le contrôle de leurs données personnelles, modifie radicalement les politiques de conservation à long terme des données et métadonnées archivées, ce depuis leur collecte, désormais soumise aux conditions de licéité de l’article 6 du RGPD (essentiellement accord de la personne concernée, ou obligations réglementaires), jusqu’au traitement du sort final des informations conservées.
Dans le cadre de l’archivage de documents électronique à valeur probatoire, la modification des documents n’est pas envisageable (pour des raisons d’intégrité documentaire). En l’état, c’est le consentement ou le caractère réglementaire qui permettra la conservation du document (une copie de pièce d’identité, par exemple). La durée de conservation et l’utilisation de cette donnée doivent être établies dans le cadre d’une politique de gouvernance des données, tout comme la réversibilité de ces données pour les utilisateurs. Nous ne reviendrons pas sur ces éléments dans ce billet, déjà décrits précédemment dans les articles de ce blog[1].
Par ailleurs, et ce sera l’objet principal de ce billet, les métadonnées associées au documents doivent également faire l’objet d’une analyse amont, afin de déterminer si leur conservation doit faire l’objet d’une attention particulière quant aux enjeux de la RGPD. Cette conservation doit se comprendre à la fois durant la durée de conservation pour usage du document, et éventuellement au-delà. Certains cas de conservation d’archives pour des raisons historiques ou statistiques, dans l’intérêt public, pourront échapper aux problématiques d’anonymisation des métadonnées au-delà de la durée d’usage. Pour tous les autres, et en particulier dans le cas de demande liées au droit à l’oubli ou à l’effacement, il sera indispensable de pouvoir garantir, de façon irréversible, leur effacement. Cet aspect du RGPD est un défi important pour toutes les solutions existantes, car il est en contradiction directe avec leur finalité qui reste de permettre et de tracer les opérations effectuées.
Nous allons donc examiner comment, et quand, dans le cycle de vie de l’archive, il faut envisager l’anonymisation des métadonnées.
Pseudonymisation des données personnelles
Sous ce nom barbare se cache, selon le RGPD dans son article 4, un « traitement de données à caractère personnel de telle façon que celles-ci ne puissent plus être attribuées à une personne concernée précise sans avoir recours à des informations supplémentaires, pour autant que ces informations supplémentaires soient conservées séparément et soumises à des mesures techniques et organisationnelles afin de garantir que les données à caractère personnel ne sont pas attribuées à une personne physique identifiée ou identifiable ». Ouf.
L’exemple type d’une mesure de pseudonymisation consiste à porter dans un référentiel externe un lien entre un identifiant unique (très certainement propre à l’application cible), utilisé en lieu et place d’identifiants personnels de type Nom-Prénom, ou numéro de sécurité sociale… La mise à disposition sécurisée, dès la collecte, de cette pseudonymisation, renforce la distance entre les données personnelles contenues dans les documents ou les métadonnées et la personne directement concernée.
Une autre possibilité de pseudonymisation consiste à faire calculer à l’applicatif ces identifiants uniques, évitant les possibilités de compromissions du référentiel externe. Des solutions à base de fonctions de hachages cryptographiques, plus ou moins complexes, éventuellement « salées », sont souvent envisagées[2]. Rappelons ici qu’une fonction de hachage cryptographique consiste à transformer du texte en un texte totalement différent, appelé hash ou condensat, avec des propriétés particulières à cette transformation :
- Deux textes identiques conduisent au même hash (pas d’aléatoire)
- Deux textes de départs proches conduisent à des hashs très différents
- Il est « impossible » de retrouver le texte d’origine à partir du hash
- Il est « impossible » (très cher en temps de calcul) de retrouver un texte de départ conduisant à un hash donné
Le salage consiste à ajouter un texte fixe ou dynamique (mais inconnu de l’attaquant) au motif initial, et ce afin de renforcer la difficulté en temps de calcul à « casser » la fonction utilisée.
Malgré tout, ces solutions techniques ne contournent pas la difficulté première qui est que face à la masse de données contenues non pseudonymisées, les recoupements peuvent conduire à identifier les personnes, ou à réduire fortement les possibilités, mettant en défaut les objectifs du RGPD. Il suffit de penser à la récente mise en ligne de données pourtant « pseudonymisée » issue de l’application Strava (géolocalisation de parcours de courses pour sportif), qui aura permis à certains d’identifier la localisation précise de bases militaires, voire d’identifier par recoupement des personnes travaillant pour les services secrets…[3]
La pseudonymisation renforce la sécurité des données personnelles, mais ne permettra surement pas une conservation permettant de s’exonérer des obligations contenues dans le RGPD, et c’est d’ailleurs une des raisons ayant conduit à la distinction faite entre anonymisation et pseudonymisation au sein du RGPD[4].
L'anonymisation des données personnelles
Il est difficile de trouver une définition précise des processus d’anonymisation. Pourtant, la loi de 1978 « Informatique et Libertés », dans son article 11, indique que les procédés techniques doivent avoir été reconnu conforme par la CNIL, qui possède un pouvoir d’homologation et de certification.
La CNIL indique, sur son site web[5], les critères d’évaluation d’une solution d’anonymisation :
- L’individualisation : est-il toujours possible d’isoler un individu ?
- La corrélation : est-il possible de relier entre eux des ensembles de données distincts concernant un même individu ?
- L’inférence : peut-on déduire de l’information sur un individu ?
Il est nécessaire, dans cet avis fourni par le G29, de valider les 3 critères pour se dispenser d’une analyse détaillée des risques de ré-indentification des personnes (c’est en particulier pour cela que la pseudonymisation n’est pas une anonymisation, puisque l’individualisation et la corrélation ne sont pas respectées).
 J’y ajouterai pour ma part un critère, mais qui n’est pas directement déduit des 3 précédents, et qui est le caractère irréversible de cette anonymisation. En effet, il faut se convaincre très tôt dans la définition des procédures de gestion de l’information concernées par le RGPD : suivant l’anonymisation, de l’information sera forcément perdue, et il ne faut surtout pas envisager de pouvoir, d’une façon ou d’une autre, la reconstruire, même partiellement.
J’y ajouterai pour ma part un critère, mais qui n’est pas directement déduit des 3 précédents, et qui est le caractère irréversible de cette anonymisation. En effet, il faut se convaincre très tôt dans la définition des procédures de gestion de l’information concernées par le RGPD : suivant l’anonymisation, de l’information sera forcément perdue, et il ne faut surtout pas envisager de pouvoir, d’une façon ou d’une autre, la reconstruire, même partiellement.
Au-delà de cet avis de la CNIL et du G29, assez général, deux grandes familles de méthodes d’anonymisation sont généralement envisagées :
- La destruction de la donnée personnelle.
- L’agrégation dans un ensemble statistique de taille suffisante.
La deuxième option concernerait par exemple la transformation d’informations collectées par agrégation au sein de cohortes. Par exemple dans une entreprise, il serait possible de conserver des informations moyennes (salaire, par exemple) pour un groupe suffisamment important, là où leur conservation au-delà d’une durée prévue ne serait pas envisageable de façon individuelle. Attention au cas d’agrégation sur des effectifs trop faibles, qui ne garantissent plus du tout leur non-inversibilité (si je souhaite détailler ces informations par age et sexe, il est indispensable que chacune des classes contienne plusieurs personnes, 2 étant bien entendu un minimum strict, mais sans doute pas satisfaisant).
Dans le cadre de l’archivage, la première méthode sera de très loin la plus souvent utilisée.
Différentes solutions techniques sont envisageables, par exemple remplacer les métadonnées concernées par des valeurs fictives génériques respectant les règles prédéfinies (numéro de matricule, prénom, nom, Adresse, identifiant…). A nouveau, ces transformations doivent être le plus destructives possibles. Conserver toute information d’origine, même partielle, comme les initiales de la personne par exemple, peut conduire, à partir de référentiel externe, à son identification… Cette opération destructive doit être vu comme un retraitement (opération archivistique) associé au traitement du sort final documentaire ou à une demande d’effacement.
Le sort des documents associés reste, sauf exception dans des cadres réglementaires, la suppression.
A quelles étapes du cycle de vie faudra-t-il envisager d'anonymiser les données ?
Deux étapes critiques dans le cycle de vie documentaire sont concernées par cette anonymisation. Il s’agit de la collecte, et de la fin de conservation des documents. Le RGPD introduit une troisième possibilité, dans les cas où elle s’applique, et il s’agit de la possibilité offerte aux personnes concernées de demander la portabilité ou l’effacement de leurs données stockées.
L’étape de collecte permet éventuellement, en cas d’anonymisation, de s’abstenir intégralement des conséquences du RGPD. Il s’agit explicitement d’une anonymisation, irréversible, ne permettant plus de faire aucun lien entre la personne et ses données. A priori, il nous semble que ces cas seront rares dans les cas d’archivage pour raisons réglementaires.
L’étape de fin de conservation (telle qu’explicitée par la politique de conservation déclarée), ou d’effacement, est associée à une exception prévue par le RGPD dans ses articles 5 et 17, exception « à des fins archivistiques dans l’intérêt public, à des fins de recherche scientifique ou historique, ou des fins statistiques ». En dehors de ce cas, il faudra anonymiser impérativement les métadonnées et supprimer (ou anonymiser dans les cas où cela est envisageable) le document archivé. Si l’anonymisation n’est pas possible, une suppression pure et simple doit être mise en place, suppression comprise comme disparition complète du document, de ses métadonnées, des références…
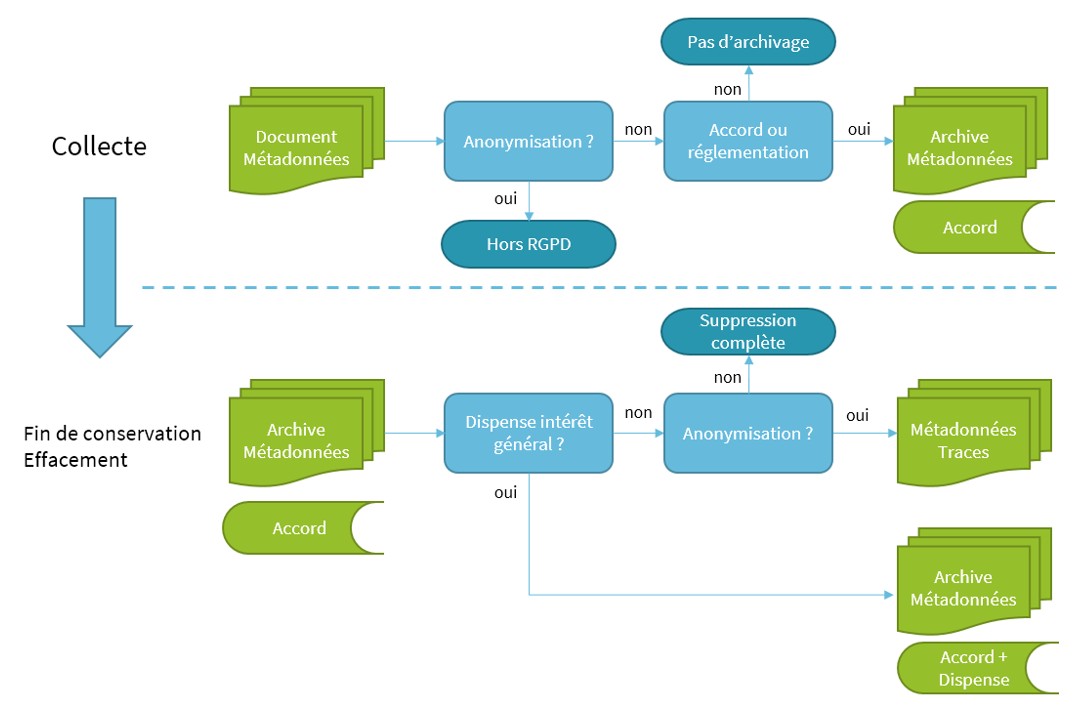
Pour conclure sur ce vaste sujet !
La possibilité de décrire finement les métadonnées associées à un document archivé, et en particulier leur caractère personnel, permet de déterminer, à la fin de la conservation initialement autorisée ou lors d’une demande d’effacement, quelles informations doivent être anonymisées. Cette opération d’effacement peut soit se faire en supprimant l’intégralité de l’enregistrement associé à cette archive, soit se faire en anonymisant de façon irréversible les informations contenues dans cet enregistrement.
Les deux solutions ont des avantages et des inconvénients. L’effacement pur et simple, difficile comme nous l’avons vu, a malgré tout l’avantage de limiter les risques associés, et de rester conceptuellement simple. Son inconvénient majeur est la disparition des historiques associés aux archives, ainsi qu’une perte d’information (pour les métadonnées qui ne seraient pas sensibles et/ou personnelles). L’anonymisation demandera une analyse à priori de la description des documents archivés, ainsi que des mesures techniques à mettre en place au sein d’une solution d’archivage. Cette anonymisation doit être irréversible, et la suppression des métadonnées, ou leur replacement par des motifs fixes (non calculés) parait le plus simple et le moins risqué.
Il reste aujourd’hui une question technique majeure, pour laquelle des solutions satisfaisantes ne sont pas existantes, et qui est la question des documents archivés, qui peuvent contenir des données personnelles. Si pour certains leur anonymisation n’aurait pas grand sens (copie de carte d’identité par exemple), pour d’autre les enjeux sont délicats. Penser l’archivage des mails, par exemple, sans se poser la question de conserver strictement les destinataires, ou la signature liée au mail, sans parler du contenu, posera problème au-delà de la durée de conservation et de l’utilisation consentie par l’utilisateur, et exposera en cas de conservation non consentie à des sanctions dans le cadre du RGPD. Envisager aujourd’hui la modification massive de ces documents pour anonymisation n’est pas une tâche aisée, voire hors de portée technique malgré les progrès des solutions d’analyse sémantique. C’est à l’aune de ces limites que la destruction pure et simple de ces documents reste la méthode la plus sûre et conforme à la réglementation.
Jérôme Besnard
Responsable R&D Spark Archives
Nous contacter :
Notes de lecture
[1] On pourra lire par exemple https://www.spark-archives.com/fr/protection-des-donnees-Route-RGPD et https://www.spark-archives.com/fr/protection-des-donnees-partie2-Route-RGPD.
[2] Pour une définition ludique et plus complète des fonctions de hachage, on pourra s’intéresser à la vidéo https://youtu.be/SccvFbyDaUI aux alentours de 2:30.
[3] On pourra lire par exemple https://lexpansion.lexpress.fr/high-tech/des-espions-de-la-dgse-identifies-a-cause-de-l-appli-sportive-strava_1987031.html pour avoir une idée du type de recoupement effectué.
[4] On lira avec attention l’article http://glorieusefrance.fr/anonymisation-et-pseudonymisation-deux-garanti... pour une analyse plus poussée des enjeux légaux de la pseudonymisation
[5] L’avis du G29 sur le site de la CNIL : https://www.cnil.fr/fr/le-g29-publie-un-avis-sur-les-techniques-danonymi...



Ajouter un commentaire