

Lors de la mise en place d'un système d'archivage, la reprise des données est l'un des chantiers primordiaux au démarrage du système. Il va, la plus part du temps, consister en l'agglomération de données existantes et disparates sur le fond comme sur la forme, puis en leur injection dans le nouveau système. Au travers de l'expérience acquise lors des différents déploiements chez nos clients, il nous est apparu que ce chantier devait être piloté comme un projet à part entière. En tant que projet, la reprise des données comporte les phases suivantes : définition du besoin, mise en projet, spécifications, conception, réalisation, recette et mise en production.
Définition du besoin
Les données reprises se répartissent en deux grandes catégories : les données relatives aux référentiels et les données relatives au stock d'archives. On trouve dans les données de type référentiel les éléments permettant la qualification des archives, les systèmes de localisation des archives, mais aussi les éléments définissants les acteurs associés aux différents processus d'archivage. Les données relatives au stock d'archives comportent à la fois la description du stock actuel mais aussi les données définissants les opérations associées : versements, demandes de sortie, destruction, …
Il appartient à cette phase projet de définir quelles données pourraient être présentes dans le système cible. C'est donc l'occasion de se poser la question d'un nettoyage des données, phase également appelée "datacleaning", ou bien d'une restructuration des données. Attention, cela pose néanmoins des questions sur la stratégie de validation des données qui sera plus complexe puisqu'il ne suffira plus de faire la comparaison entre les nouvelles et les anciennes données. Nous conseillons vivement dans la mesure du possible d'effectuer une restructuration en amont de ce chantier de reprise.
Mise en projet
Une fois le besoin défini, il convient de réaliser la mise en projet de la reprise de données notamment en définissant la stratégie de reprise des données. Pour chaque type de données, il conviendra de se poser plusieurs questions afin d'adopter la bonne stratégie de reprise :
- Où se trouve l'information (centralisée dans un ou plusieurs systèmes informatiques, dans des documents procéduraux, etc) ?
- Qui peut juger de la pertinence de l'information et de sa conservation (et définir les règles de gestion de mapping éventuelle) ?
- L'information est-elle vivante ? Si oui, les stratégies d'extraction et de transformation manuelles sont à exclure.
- Quelle est la volumétrie à intégrer ? Si la quantité est importante, les stratégies d'extraction et de transformation manuelles sont également à exclure.
- Qui va effectuer l'extraction et la transformation (Il est vivement conseillé voir indispensable de s'appuyer sur un profil technique afin d'automatiser le processus et le rendre répétable) ?
- Quelles sont les indicateurs de succès de la reprise (comptage, vérification métier sur un échantillon de données...)
- Quelle la durée acceptable d’interruption de l'activité archivistique (entre le système existant et le nouveau système)
- Comment sécuriser ce chantier de reprise de données situé sur le chemin critique ? (le lotissement et l'échantillonnage est préconisé afin de valider des quantités raisonnable de donnée avant de se lancer sur un processus complet qui risque d'être beaucoup plus long)
Comme dans tout projet, lors de cette phase on définira planning, acteurs, livrables, risques et moyens.
Spécifications :
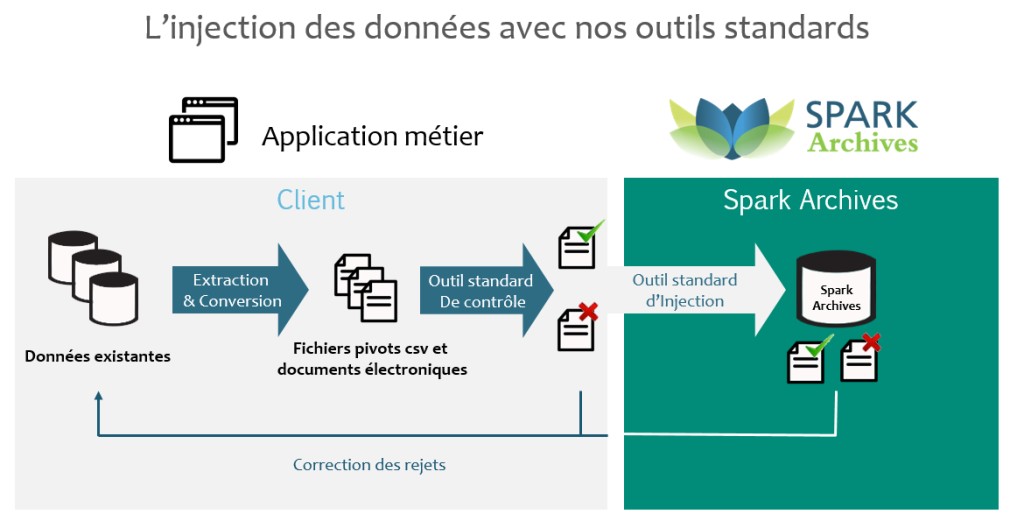
Le système cible attend des données à un format et une organisation qui lui est propre. La reprise des données dans Spark Ajantâ s'appuie sur un outil standard d'injection des données en masse. Cet outil est capable d'injecter, à l'aide de fichiers plats, les métadonnées relatives aux archives. C'est pourquoi le format des fichiers pivots utilisé est standardisé. Les spécifications s'attachent ici à préciser les métadonnées propres à un paramétrage client.
Réalisation :
Les problématiques de transfert d'informations structurées d'un système dans un autre sont souvent solutionnées par des outils de type ETL : "Extract - Transform - Load" qui procède en 3 étapes comme son nom l'indique : extraction, transformation, chargement.
Le fait de réaliser l'extraction et la transformation des données via un ou plusieurs programmes informatiques va permettre de plus simplement itérer et corriger les données lors des phases de validation de celle-ci.
L'étape de chargement des données est standard à Spark Ajantâ. En revanche, les parties d'extraction et de transformation dans le format pivot sont propres à chaque client et à son système d'informations existant. Pour aider ses clients dans cette tâche, Spark Archives fourni un outil de vérification des données nommé LORD. Cet outil automatise la vérification de la conformité des fichiers avec les spécifications définies. Les vérifications portent sur la forme des fichiers et des données le composant mais aussi sur la cohérence des fichiers entre eux.
Tests/Recette
Afin de converger au mieux avec ses clients, Spark Archives propose une méthodologie reposant sur la planification des 3 itérations de tests avant la mise en production. La première itération vise à valider les données de référentiel. La deuxième itération vise à vérifier que les corrections sur les données de référentiel sont effectives et à valider les données de stock d'archives. La troisième itération de contrôle s'assure que les différentes corrections sont effectives. Il s'agit d'un travail par escalier.
Risques et écueils
Comme tout projet, la reprise des données comporte ses risques et écueils. Quelques retours d'expériences :
- L'exécution de l'extraction et de la transformation se réalise d'autant mieux que la stratégie a été correctement définie.
- Une analyse critique des données existantes est nécessaire avant d'en planifier l'injection dans Spark Ajantâ. Comme nos amis anglo-saxons le disent si bien : "shit in, shit out".
- Une des difficultés opérationnelles dans la tenue des tests réside dans les temps d'exécutions qui, pour des volumes importants peuvent durer plusieurs heures voire jours. En effet, la manipulation de millions de données et leur enrichissement fonctionnel dans le modèle Spark Ajantâ requiert un temps de calcul certain. C'est pourquoi, il ne faut pas sous-estimer le délai nécessaire à la convergence sur les données.
- Il convient de s'interroger sur les problématiques RGPD liées aux données manipulées. Anonymiser les métadonnées peut être réalisé simplement, en revanche, la gestion des archives électronique peut être plus délicate.
En synthèse
Les grandes règlent à retenir sont les suivantes :
- La reprise des données est un projet à part entière.
- Il ne faut pas négliger l'importance de ce chantier notamment en termes de moyen humain que ce soit en terme de réflexion sur l'information mais aussi de réalisation et de tests.
- Il est préférable de s'appuyer sur des profils techniques pour simplifier les itérations de correction / validation des données reprise.
- La qualité de vos données participe grandement à la qualité perçue de votre système d'archivage alors prenez bien soin de vos données existantes.
Fréderic PERDU
Responsable Service Clients – Directeur de projets
Mathieu CATHARY
Responsable de la R&D projet


