

Harmoniser au niveau mondial les règles de la description archivistique n’est pas un exercice simple : la variété des objets à décrire, leurs sujets, leurs formes, le contexte dans lesquels les objets ont été produits, et l’environnement culturel dans lequel évolue celui qui décrit… sont autant de défis à relever.
Ils sont cependant essentiels pour ceux qui souhaitent accéder aux archives, que ce soient les producteurs eux-mêmes ou les lecteurs extérieurs à l’organisation productrice, comme les chercheurs, les généalogistes, ou toute personne intéressée par la consultation des documents.
Ainsi, pouvoir accéder à des descriptions dont la forme est semblable partout dans le monde parce qu’elle a été normalisée est non seulement une garantie de gain de temps pour les utilisateurs, mais également une condition préalable aux échanges de descriptions qui ont lieu entre certains services d’archives afin de donner une visibilité croisée sur leurs fonds d’archives.
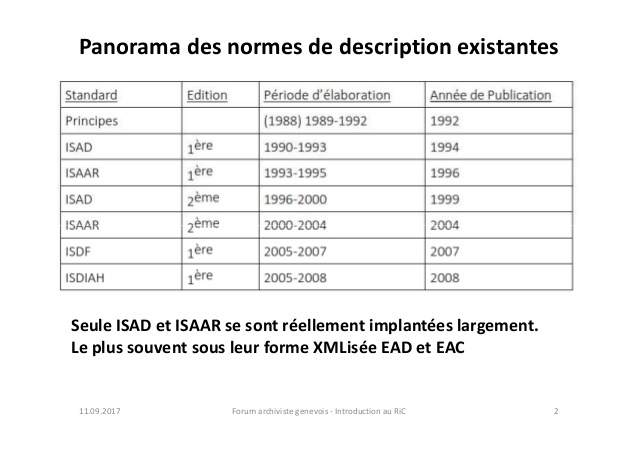
C’est ainsi que le Conseil international des archives a réalisé, par quatre fois, de 1994 à la fin des années 2000 des textes normatifs consensuels utilisés internationalement pour fixer les règles de description, avec les normes
- General International Standard Archival Description (ISAD(G))
- International Standard Archival Authority Records—Corporate Bodies, Persons, and Families (ISAAR(CPF))
- International Standard for Describing Functions (ISDF)
- International Standard for Describing Institutions with Archival Holdings (ISDIAH)
Cependant, l’extension formidable depuis la fin du vingtième siècle des possibilités d’accéder à l’information a considérablement modifié les pratiques de consultation : recherche et accès en temps réel, visualisation arborescente de l’objet dans le fonds, etc….
Afin de s’adapter à ces nouvelles pratiques, aux outils et aux possibilités offertes par ces outils, l’ICA a entamé dès 2012[2] un travail titanesque, destiné à faire évoluer la manière de décrire les objets d’archives à partir des règles de description archivistique existantes : le standard Records in Context (RiC). Ce standard est composé de deux parties, l’une étant le modèle conceptuel : RiC-CM, et l’autre l’ontologie (Ric-O).
Qu’est-ce que RiC a de plus que les 4 textes fondateurs ?
Les experts du groupe EGAD s’accordent tous à dire que la norme ISAD(G) est inscrite dans un contexte temporel particulier, pré-digital.
Dans ce contexte, même si la construction des instruments de recherche via des outils informatiques comme les logiciels d’édition en xml-EAD est possible, la finalité première est de produire des instruments de recherche au format physique, avec une structure hiérarchique à niveaux, en partant du niveau le plus important (le fonds) pour arriver à la plus petite unité de description, soit la pièce, soit l’article, en accord total avec le principe premier de respect des fonds, à l’origine de la discipline archivistique.
De même, la norme ISAD(G) oblige à ce que l’instrument de recherche rédigé soit totalement autoporteur : on devait pouvoir comprendre les objets décrits en ne se référant qu’au seul instrument de recherche.
La fin de la description hiérarchique par niveaux ?
Pas de panique ! RiC ne sonne pas le glas de la description hiérarchique et, non, il ne faudra pas réécrire tous vos instruments de recherche !
Le groupe d’experts a constaté que sur un usage intensif de la norme ISAD(G) depuis 1994, il y avait une persistante d’écarts, entre la manière d’envisager la description intellectuelle, l’organisation des fonds, et les outils de gestion des archives essentiellement basées sur des technologies de bases de données.
Ces écarts ne sont pas en soi problématiques pour des fonds encore quantifiables et traitables par un être humain, mais que cette approche s’avère très rapidement limitative lorsqu’on s’attaque à la description des fonds purement électroniques.
Par ailleurs, les usagers des archives sont également par la force des choses, des personnes dans leur temps, et donc des utilisateurs de nouvelles technologies. Parmi ces technologies, la représentation graphique de données, ou data visualisation, est particulièrement appréciée : pour quiconque veut valoriser ses archives, cet argument est particulièrement important.
Pour rencontrer ces attentes, l’EGAD a donc réfléchi sur la conception d’un modèle où le lien entre les objets archives ne serait plus uniquement hiérarchique, mais relationnel, englobant toute la richesse et la complexité des relations entre ces objets : le groupe définit par ailleurs le modèle RiC comme un modèle sémantique et structurel destiné à produire des « descriptions multidimensionnelles » : il s’agit de donner à voir le fonds dans son contenu mais aussi dans un contexte plus large. Le groupe devient le nouveau paradigme dans lequel les objets archives s’entendent, se structurent, se complètent à travers d’autres type de représentation qui peuvent être spatiales, temporelles, ou thématiques en s’affranchissant, sans la remettre en question, de l’unité de description archivistique.
Ainsi, le modèle conceptuel de RiC décrit, à partir du contenu des quatre normes de description, les principales entités de description, les propriétés et attributs de ces entités et les relations entre elles.
L’ontologie, application pratique du modèle conceptuel et le web sémantique
Si le modèle conceptuel de RiC est stabilisé, l’ontologie, c’est-à-dire l’application « pratique » du modèle conceptuel en est aux phases préliminaires, essentiellement parce que l’ontologie doit suivre en tous points la première partie du standard, actuellement mise à jour.
Ainsi, l’objectif de RiC-O (O pour ontologie) est de traduire le modèle conceptuel dans le langage OWL 5 standardisé par le W3C, et basé sur le standard RDF pour Resource Description Framework.[3]
Nous avons évoqué plus haut le goût des utilisateurs des archives pour les nouvelles technologies et la représentation des données : c’est l’objectif du modèle RDF, qui organise l’information sur une ressource en triplet (sujet, prédicat, objet).
Prenons l’exemple d’une facture n° 2309 de fournitures d’un pot à crayons émise par la société X pour la société Y le 22 mars 2018.
On pourra ainsi décrire cette ressource pas plusieurs triplets (en rouge les sujets, en noir les prédicats, en bleu les objets) :
- Document n°2309 a pour typologie facture
- Document n° 2309 a pour objet fourniture de pot à crayon
- Document n° 2309 a pour auteur société X
- Document n° 2309 a pour date de création le 22 mars 2018
- …
Et grâce au modèle RDF, vous avez la possibilité de qualifier le lien entre le sujet et l’objet, ce qui permet la modélisation graphique de ces liens et exploiter vos données de description pour tous types d’usages : valorisation, quantification, retraitement des données…
Le choix de ce standard OWL n’est pas anodin : l’un des objectifs majeurs de RiC, revendiqués par le groupe EGAD, est aussi de pouvoir aligner les règles de description archivistiques avec les standards des autres professions du secteur de la culture et du patrimoine, réduisant ainsi les risques d’éparpillements, pour offrir un accès unifié aux ressources culturelles.
Une adaptation française de la première version de RiC-O a déjà été menée[4] , pouvant permettre ainsi aux services d’archives de pouvoir concrètement appréhender la modélisation des jeux de données et comprendre comment utiliser le prototype.
Mais que fait Spark Archives dans tout ceci ?
Les travaux menés sur le standard RiC sont intéressants pour nous en tant qu’éditeur à plus d’un titre. La description archivistique est un des fondamentaux du métier d’archiviste. Pouvoir suivre en amont le travail normatif et ses applications nous permet d’anticiper les changements structurels et fonctionnels des produits que nous proposons.
Cela nous permet donc de bien comprendre les exigences du métier afin de les intégrer de manière opérationnelle et ainsi couvrir les besoins des utilisateurs finaux et de la communauté archivistique, garante de la gouvernance et de la pérennité des données dans le temps.
Pour en savoir plus, rendez-vous bien sûr au prochain Forum des archivistes de l’Association des Archivistes Français où le sujet sera abordé par les spécialistes du domaine : https://forum.archivistes.org/motcle/records-in-context-ric/
Et, en attendant, vous pouvez toujours patienter en consultant :
https://siaf.hypotheses.org/493
https://www.ica.org/fr/node/14664
Charlotte Maday, Consultante Spark Archives
[1] Schéma accessible à l’URL : http://www.forumdesarchivistes.ch/2017/10/02/forum-du-11-septembre-2017-records-in-context/ [diapositive n°2]
[2] Travail mené sous l’égide du groupe expert sur la description des données (EGAD)


